データベースは大量のデータを保存し、必要に応じて検索・更新・削除などの操作を行うことができるもので、ユーザデータやログ等を保存するために利用されます。
代表的なデータベースの種類には、リレーショナルデータベースやNoSQLデータベースなどがありますが、AWSのRDSは、リレーショナルデータベース専用のマネージドサービスで、データをテーブル(表形式)を使って管理し、SQLと呼ばれるクエリ言語で操作を行います。NoSQLデータベースサービスとしては、RDSとは別にAmazon DynamoDBがあります。
ここでは、AWS RDSサービスのデータベースの種類や使い方について紹介します。
Contents
RDSの種類
AWSのRDSサービス(Relational Database Service)には、大きく分けると「Amazon RDS」と「Amazon Aurora」という2つのサービスがあります。RDSの中にRDSと別物?と思うかもしれませんがイメージとしては下図のようになっています。
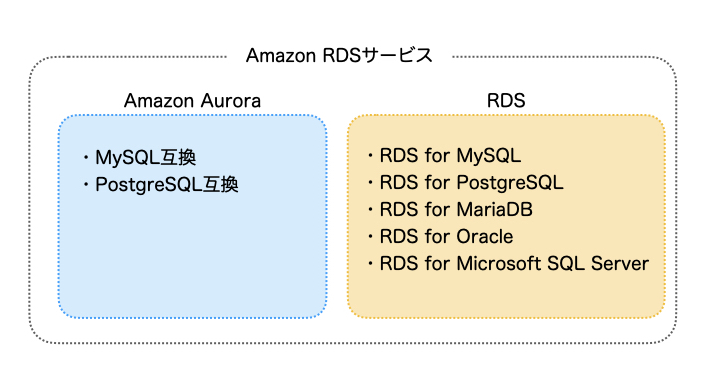
RDS for XXについては、EC2インスタンスにMySQL等のデータベースエンジンがインストールされたものと大差ありません。そこにストレージとしてEBSが繋がっていて、データが蓄積されます。EBSは2台存在しており、ミラーリングすることで耐久性を高めています。レプリカを作成する場合はこのセットがもうひとつ別のAZで作成され、さらに耐久性・安定性を高められます。
Amazon Auroraは、RDSファミリーの中でもAWSが独自に設計したリレーショナルデータベースサービスです。高いパフォーマンスと可用性を提供するように設計されており、通常のMySQLやPostgreSQLと比べて最大5倍(MySQL互換の場合)または3倍(PostgreSQL互換の場合)のスループットを実現します。
RDS for XXと大きく異なる点は、インスタンスとストレージが分離していることです。下図のようにプライマリインスタンスとレプリカひとつがデフォルトで作成されます。さらにストレージが、1AZあたり2箇所、3AZに渡りコピーされていて6箇所のストレージで構成されたクラスターボリュームが作成されます。プライマリからはRead/Write、レプリカからもReadが同じクラスターボリュームに対して参照できます。この6つのストレージは互いに通信し、もしいずれかのストレージがデータ消失などした場合は修復し合う仕組みになっています。ストレージは自動的に拡張され、最小10GBから最大128TBまでスケーラブルに拡張します。
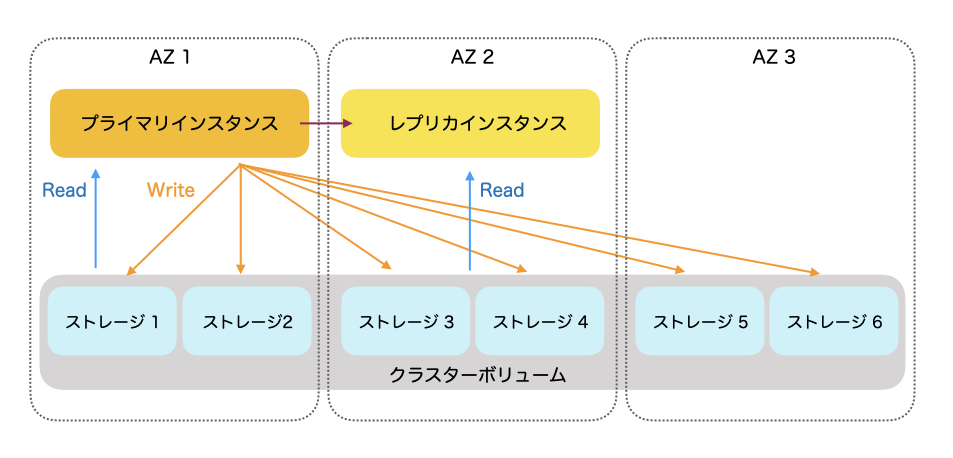
データベースとしてのインタフェースはMySQL互換やPostgreSQL互換で、通常のデータベースと同様に利用できます。デフォルトでマルチAZ化されているため、高い耐障害性やパフォーマンスが必要な時に便利です。
データベースの設定
AWSのRDSサービスに移動して、「データベース作成」ボタンをクリックします。データベースエンジンの選択で、上記で記述したデータベース種類の中から選びます。

選択後、DBインスタンスの識別子や、データベースの管理者ユーザー名とパスワードを設定します。
データベースを配置するVPCやサブネットを選択して、データベースを作成します。データベースを利用するEC2インスタンスやLambdaと同じVPCに配置することをおすすめします。
作成されたデータベースの「エンドポイント」と「ポート」を確認します。これらはデータベースに接続する際に必要になります。また、セキュリティグループの設定も必要で、データベースにアクセスするクライアントを許可するために、「インバウンドルール」に、データベース接続用のプロトコル(MySQLの場合はTCPポート3306など)とアクセス元のIPアドレスもしくはセキュリティグループを追加します。
ここまでできれば、データベースへのログインが可能になります。MySQLの場合、以下のコマンドを実行してRDSに接続できます。
mysql -h <エンドポイント> -u <マスターユーザー名> -p<エンドポイント>にはRDSのエンドポイントを、<マスターユーザー名>には設定したマスターユーザー名を入力し、-pを指定することでパスワード入力を促されます。ポート番号が3306以外の場合は、-Pオプションで指定できます。
コマンドが成功すれば、RDSデータベースにログインして操作を開始でき、あとはSQLコマンドで操作ができます。
DBのマイグレーション
システム開発や運用をしていると、データベースのスキーマ(テーブルやカラムなどの構造)を変更することがあると思います。DBのマイグレーションとは、これらをバージョン管理し、変更を効率的に行うための仕組みです。以下では、代表的なマイグレーションツールである golang-migrateを紹介します。
golang-migrateは、マイグレーションを実行するためのファイルが必要です。ファイルはSQLで書かれたもの(.sql)か、Goのコード(.go)で記述できますが、一般的にはSQLファイルが多く使われます。
マイグレーションファイルは、「up」ファイルと「down」ファイルの2つで構成され、それぞれ以下の役割を持ちます。
- upファイル:データベーススキーマを変更(アップグレード)するSQL文を含む。
- downファイル:upファイルで行った変更を元に戻す(ダウングレード)ためのSQL文を含む。
upファイルとdownファイルの例を書きます。
upファイルの例です。(1_create_users_table.up.sql)
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL
);downファイルの例です。(1_create_users_table.down.sql)
DROP TABLE users;ファイル名は、<version>_<description>.<up|down>.sql という名前が慣習的に用いられ、upファイルとdownファイルは対になっています。
データベースのスキーマのアップデートを行う場合は、golang-migrateコマンドを次のように実行します。
migrate -path <マイグレーションファイルのパス> -database <データベースURL> upマイグレーションファイルのパスにはupファイルやdownファイルのあるフォルダを指定します。
アップデートしたけど元に戻したい場合は、
migrate -path <マイグレーションファイルのパス> -database <データベースURL> downとするとそのバージョンへのアップデートが無かったことになります。ひとつ前に戻ります。最初までは戻りません。
特定のあるバージョンへマイグレーションを行いたい場合は、以下のように指定します。
mimigrate -path <マイグレーションファイルのパス> -database <データベースURL> goto <バージョン番号>マイグレーションの状態はデータベースのschema_migrationsテーブルに保存されているので、バージョン情報などを確認することができます。
このようにマイグレーションツールを使うことによって、データベースのスキーマを簡単にバージョン管理でき、スキーマの変更やロールバックも容易に行え、ミスる可能性も減らせます。