大規模言語モデル(LLM)の登場により、検索の世界が変わりつつあります。これまではキーワードをいくつか入力し、それに関連するドキュメントを検索するような使い方でしたが、LLMによって自然文での検索や自由度の高い検索が可能になりました。
しかしながら、大規模言語モデルが学習しているデータは概ね公知となっている一般的な常識に基づいたものが多いです。したがって、一般的な質問であれば真っ当な回答が得られますが、特定の社内情報など学習されていない秘密情報等については当然ながら回答できないです。
そこで、LLMリクエストする質問のプロンプトを上手く利用して、特定の情報への質問も可能なようにする技術が検索拡張生成 RAG(Retrieval Augumented Generation)です。ここでは、RAGの概要とちょっとした実装例を紹介いたします。
RAGの概要
RAGとは、上記のような特定の情報の中から必要な情報を検索したり、内容を質問して回答を生成してもらう(Q&A)を可能にする仕組みです。簡単にやるのであれば、プロンプトに全ての情報を詰め込み、最後に検索や質問をつけてLLMにリクエストすることでできなくは無いです。ですが、プロンプトのサイズには制限がありますし、不要な情報まで詰め込むことで処理速度も下がり、コストもかかります。ですので、検索や質問に関連しそうな部分だけをプロンプトに詰め込んで送るというのがRAGの基本的な仕組みとなります。
RAGのサーベイ論文の図を引用しますと、まずプロンプトエンジニアリングというものがベースとしてあり、RAGは特定の外部情報などを必要とする場合に拡張するもの、一方ファインチューニングはモデル自体をチューニングするため、ドメイン適応などに適していると説明されています。
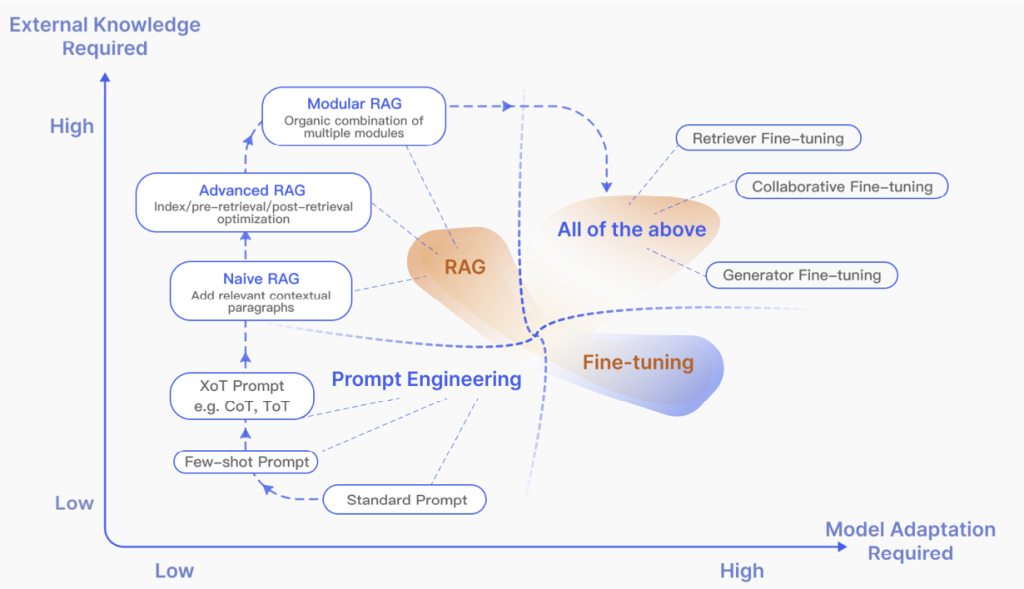
もちろん、RAGとファインチューニングは排他的では無いので両方を組み合わせることで両方の良い部分を享受できるようになります。
RAGの処理フロー
RAGの基本的な処理フローを書きます。LLMのモデルにが学習されていない外部情報となるドキュメントがあり、それに対してユーザが質問や検索をして、回答文を生成するというシナリオの処理フローになります。
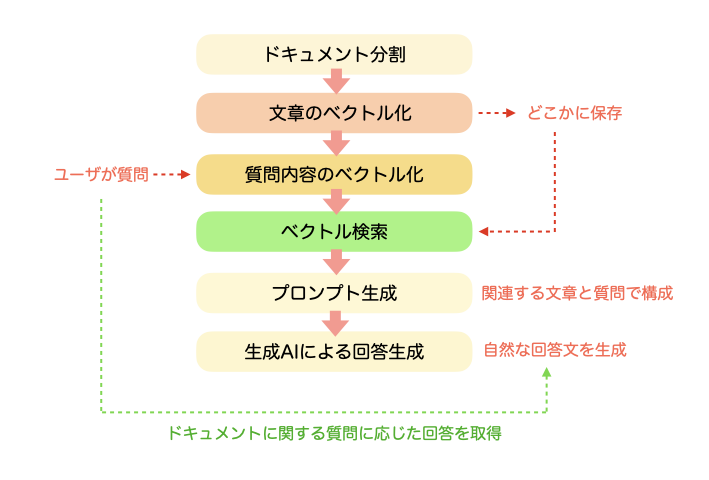
まず外部情報となるドキュメントを分割して、文章単位にします。この文章をベクトル化し、ベクトルの形式で保存しておきます。次にユーザが質問や検索を自然文で入力します。このユーザの質問文もベクトル化します。このユーザの質問文のベクトルと、外部情報として保存してある各文章のベクトルをベクトル検索で比較してベクトルが近いものをピックアップします。ピックアップしたベクトルの文章とユーザの質問文をプロンプトにいれてLLMにリクエストするプロンプトを生成します。このレスポンスが回答文となります。
この一連の処理フローの中でキーとなる技術を列挙しますと
- ドキュメントの分割
- 文章のベクトル化(Embedding)
- ベクトル検索
- プロンプト生成
となります。これら全てを提供してくれるフレームワークとして、LangChainやLlamaIndex等があります。特に重要となる部分が文章のベクトル化で、ここは大抵はSBERT(Sentence BERT)というものが利用されます。
文章をベクトル化できてしまえば、ベクトル検索の部分はベクトルのコサイン類似度等を計算すれば類似度比較ができますので、やはりベクトル化の部分が重要になってきます。
SBERT (Sentence BERT)
SBERTとは、事前学習されたBERTモデルを使い、類似する文章のベクトルが近くなるようにファインチューニングされたもので、文章の類似度を比較する文章ベクトルを生成するのに適しております。
上記の論文の図を引用しますが、あらかじめ類似する文章のペアを(類似しない文章のペアも)ファインチューニングデータとして使い、2つのBERTモデルにそれぞれを入力して出力されたベクトルを演算し、Softmaxの分類器で類似・非類似のラベルを出力するモデルを学習させます。
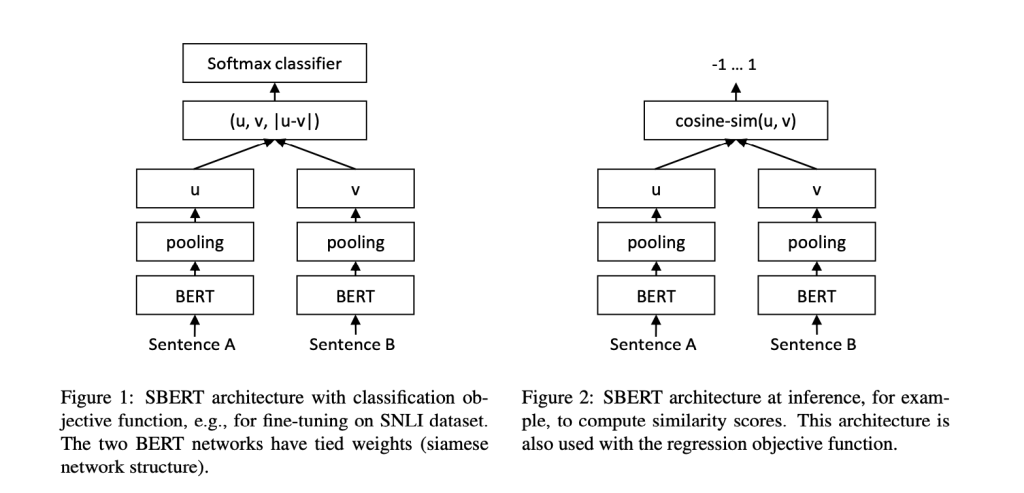
この学習過程で、各BERTモデルは類似度計算に適した文章ベクトルを出力できるようにチューニングされていきます。このファインチューニングされたBERTモデルをSBERTと呼び、さまざまな文章タスク(類似度、文書分類など)に利用できます。
Sentence Transformer
SBERTを簡単に試せる実装として、sentence-transformerがあります。ここではsentence-transformerを使って文章をベクトル化し、類似度を計算する例を紹介します。
pythonを使います。sentence-transformerのインストールは簡単です。ベクトル
# pip install sentence-transformers文章をベクトル化して比較するサンプルプログラムをこちらのhuggingfaceのサイトを参考に掲載します。
from sentence_transformers import SentenceTransformer, util
docs = ["外部情報1を入れます。", "外部情報2を入れます。"]
query = "ユーザの質問文を入れます。"
#Load the model
model = SentenceTransformer('sentence-transformers/multi-qa-MiniLM-L6-cos-v1')
#Encode query and documents
query_emb = model.encode(query)
doc_emb = model.encode(docs)
#Compute dot score between query and all document embeddings
scores = util.dot_score(query_emb, doc_emb)[0].cpu().tolist()
print(scores)docsには、検索対象となるドキュメントの文章をリストで格納します。queryには質問となる文章を入れます。modelはいろいろありますが、マルチリンガルでそれほど大きく無いモデルを利用します。modelのencode関数で文章をベクトル化でき、384次元のベクトル値に変換されます。dot_scoreという関数を使えば、これらのベクトルの類似度を計算してスコア化してくれます。
コサイン類似度
コサイン類似度とは、2つのベクトルの角度が近いか正反対かを示すもので、ベクトルの類似度に利用されます。角度が一致するものが1、正反対のものが-1となります。計算方法は、2つのベクトルの内積を距離の積で割ることで算出できます。
上記はpythonで実装しているので、ベクトル同士の類似度計算(コサイン類似度)も用意されていますが、もし実装言語でそういった便利なものがない場合は下記のように計算できます。フロントで実装することを考慮して javasciptで記載します。
function cosine_similarity(vec1, vec2){
var dot = 0;
var dist1 = 0;
var dist2 = 0;
for(i = 0; i < vec1.length; i++){
dot += (vec1[i] * vec2[i]);
dist1 += (vec1[i] * vec1[i]);
dist2 += (vec2[i] * vec2[i]);
}
dist1 = Math.sqrt(dist1);
dist2 = Math.sqrt(dist2);
var similarity = dot / (dist1 * dist2)
return similarity;
}
使い方の例も書きます。
let a = [1.2, -1.3];
let b = [1.3, -1.2];
let c = [-1.1, 1.1];
let sim;
sim = cosine_similarity(a, b);
console.log(sim);
sim = cosine_similarity(a, c);
console.log(sim); aとbは似ているので0.99ぐらいの値が、aとcは真逆なので -0.99ぐらいの値がでてきます。
もし、ベクトル値が文字列で保存されていたり、受け取ったりした場合は下記のように変換すれば上記と同様に計算できます。
let a = ['1.2', '-1.3'];
a = a.map(str => parseFloat(str));